SCHRIFTARTEN / SCHRIFTDATEN

2025-09-02 – 2025-09-02
Supervised by: Kim Albrecht
Related Courses: Master Colloquium Information Design | SS25
Einleitung
"Schriftarten / Schriftdaten" ist eine umfassende Datenbank digitaler Schriftarten. Betrachtet werden dabei nicht nur gängige Metadaten wie Gewicht, Stil, Autor*innen, etc., sondern auch konkrete gestalterische Parameter wie Strichstärke, Kontrast, Höhen, Breiten und weitere. Insgesamt gibt es für jede Schriftart über 100 und für jede Familie über 50 distinkte Merkmale, die alle empirisch erfasst und ausgewertet werden können. Die relevanten Parameter wurden manuell aus verschiedenen Werken zur Schriftgestaltung gesammelt (u. A. "The Visual History of Type" von Paul McNeil). Die Schriftdateien wurden von verschiedenen öffentlichen Webseiten mit Hilfe von eigens-entwickelten Scrapern geladen und in einer Postgres-Datenbank angelegt. Die Erfassung erfolgt größtenteils automatisch durch Bibliotheken wie Opentype.JS und Fonttools.
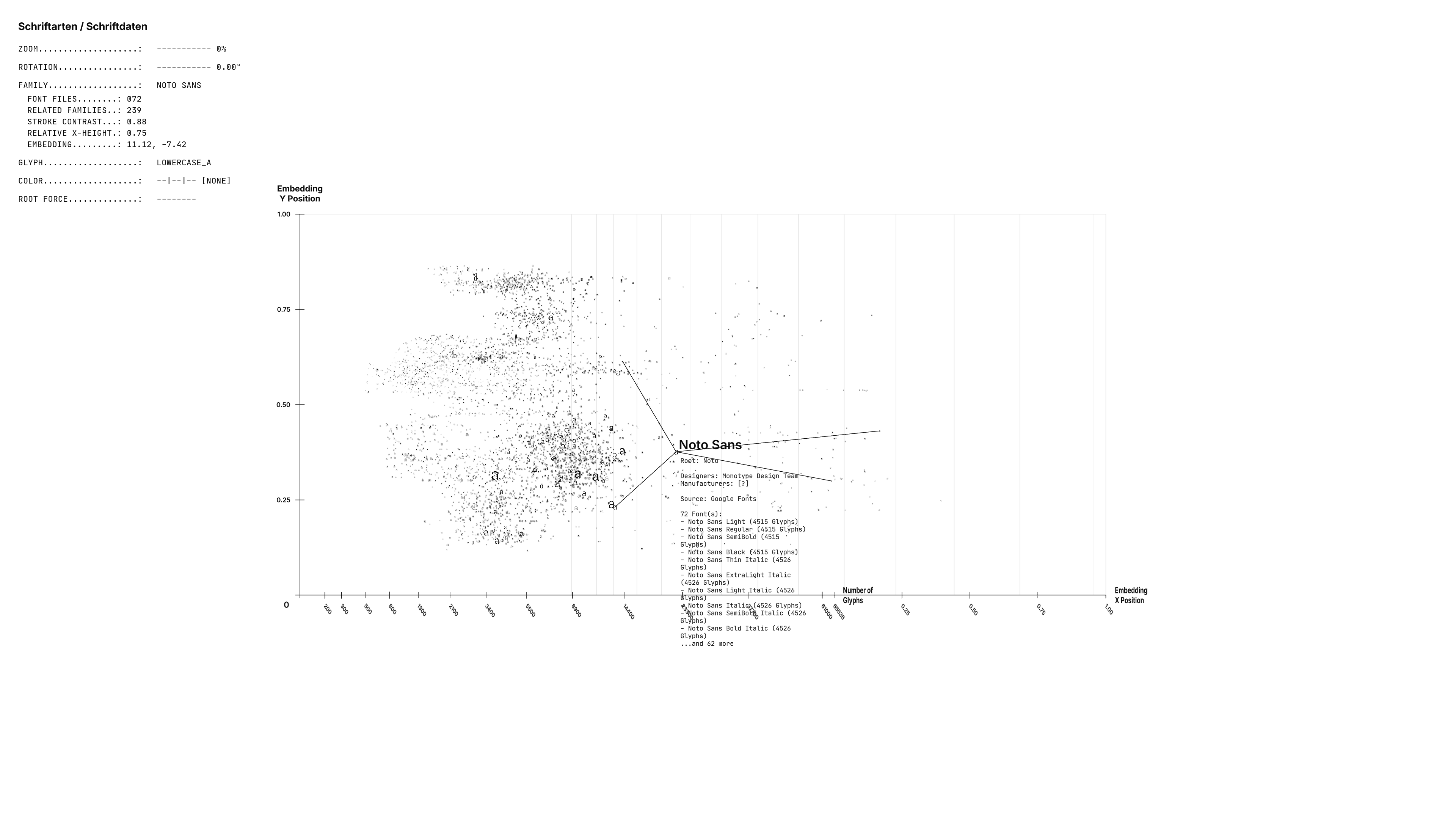
Um diese ersten Ergebnisse darzustellen, wurden die ASCII-Glyphen als Bilder rasterisiert und anschließend durch den Dimensionalitätsreduktionsalgorithmus "PaCMAP" auf 2 Dimensionen reduziert. Dadurch entstehen Cluster von Schriftarten mit ähnlichen visuellen Eigenschaften. In einer interaktiven Visualisierung, die mit SvelteKit und ThreeJS im Browser realisiert wurde, lassen sich nun durch das Hinzufügen weiterer Dimensionen (z-Position, Farbe, Größe, etc.) wesentlich intuitiver neue Zusammenhänge erkennen. Das Projekt dient als Vorstufe für meine Masterarbeit, die sich konkreter mit der Analyse der Daten und dem Generieren neuer experimenteller Schriftarten beschäftigen wird.
Datensammlung
Heutzutage haben wir den Luxus, dass ein großer Teil der Schriftarten im Internet mit offenen Lizenzen frei erhältlich sind. Größere Webseiten wie Google Fonts, Fontshare oder Open Foundry bieten eine Vielzahl von Schriften und teilweise schon einige strukturierte Metadaten an.
Mit Hilfe von Webscraping können diese Daten vollautomatisiert heruntergeladen und vorsortiert werden. Bestehende Metadaten können so ebenfalls in ein einheitliches Format überführt werden. Darunter fallen auch viele Informationen, die bereits (versteckt) in den Schriftdateien selbst enthalten sind. Tools wie OpenType.JS oder Fonttools können diese Metadaten (bspw. die Höhe der Buchstaben oder die Anzahl an Glyphen) recht einfach extrahieren. Weitere Daten können später über die Analyse der eigentlichen Vektordaten gesammelt werden.
Auch Adobe bietet Schriftarten öffentlich auf ihrer Website an. Auch wenn diese kommerziell sind, sind die Vorschau-Versionen und Metadaten für alle sichtbar. Hier ergibt sich dennoch ein gewisser Graubereich und es entstehen schnell Fragen über die Ethik und Legalität von Scraping (insbesondere mit der Motivation, die Daten für generative Modelle zu verwenden). Diese Fragen bilden weiterhin eine große Herausforderung und müssen spätestens in der nachfolgenden Arbeit adressiert werden.
Zusätzlich habe ich auch die Seite "fontsinuse.com" als weitere Quelle herangezogen. Fonts In Use bietet ebenfalls Informationen zu Autor*innen, verwandten Schriftarten und vor allem aber Daten zu ihrer Verwendung in verschiedenen Kontexten. Diese Daten fließen nicht direkt in die Visualisierungen ein, sondern dienen lediglich als Querverweis.
MSDF Atlas Gen

"MSDF Atlas Gen" ist eine Software basierend auf "MSDFGen" vom selben Autor. Wie der Name bereits verrät, generiert dieses Tool einen Atlas von sogenannten MSDFs (Multi-Channel Signed Distance Fields). MSDFs sind eine neuere Technik, die es ermöglicht, Vektorgrafiken in rasterisierten Texturen darzustellen, dabei aber noch relativ gut skalierbar zu bleiben (also ohne unscharf zu werden). Sie sind in erster Linie für Text in 3D-Anwendungen gedacht.
Hier ist der Vorteil, dass wir die Daten in immer gleicher Größe (Pixelgrafiken mit 64x64x3 Punkten) generieren können, ohne dabei viel Qualität gegenüber der Vektorgrafik in der Darstellung zu verlieren. Ein einfacher GLSL-Shader kann diese MSDF-Daten wieder als normale Schriftzeichen ohne die typischen Unschönheiten von skalierten Rastergrafiken darstellen:
varying vec2 vUv;
varying vec2 vGlobUv;
varying float highlight;
uniform sampler2D uTexture;
uniform vec3 color;
uniform float cameraDist;
float median(float r, float g, float b) {
return max(min(r, g), min(max(r, g), b));
}
float screenPxRange() {
vec2 unitRange = vec2(6.0) / vec2(textureSize(uTexture, 0));
vec2 screenTexSize = vec2(1.0) / fwidth(vUv);
return max(0.5 * dot(unitRange, screenTexSize), 1.0);
}
void main() {
vec4 msdf = texture2D(uTexture, vUv );
float distance = median(msdf.r, msdf.g, msdf.b);
float pxDistance = screenPxRange() * (distance - 0.5);
float borderWidth = 0.5;
float mask = clamp(pxDistance + 0.5, 0.0, 1.0);
mask *= smoothstep(borderWidth, borderWidth + 0.01, distance);
vec3 useColor = color;
float circleRadius = mix(0.5, 0.0, cameraDist);
float circle = smoothstep(circleRadius, circleRadius - 0.01, length(vGlobUv - vec2(0.5)));
vec4 circleColor = vec4(useColor, circle);
float blendFactor = cameraDist;
vec4 msdfColor = vec4(useColor, mask);
gl_FragColor = mix(circleColor, msdfColor, blendFactor);
}
Dimensionalitätsreduktion
Diese 64x64x3-Datenblöcke können nun sehr einfach auf 1 Dimension abgeflacht (als 12288-dimensionale Vektoren bspw.) und anschließend an PaCMAP übergeben werden. PaCMAP generiert daraus eine Liste an 2D-Vektoren die jeweils einer Schriftart zugeordnet werden können.
Visualisierung
Die Visualisierung zeigt alle gesammelten Schriftfamilien als einen einzelnen Punkt. Jede Familie wird dabei durch einen einzelnen Schnitt repräsentiert (möglichst "Regular, Non-Italic"). Dadurch werden Dinge wie Strichstärke und Stil ausgeschlossen und PaCMAP kann sich auf andere Parameter konzentrieren. Auch die Menge an Daten reduziert sich dadurch um ein Vielfaches. Statt 60.000+ Punkte für alle Schriftschnitte werden nur ca. 4000 dargestellt, was die Performance der Visualisierung erheblich verbessert.
Dazu kommt eine dritte Dimension für die Punkte: Die durchschnittliche Anzahl der Glyphen der Familie wird auf der z-Achse dargestellt. So entsteht eine Differenzierung zwischen bspw. einfachen Display-Fonts, die oft weniger Glyphen haben und großen kommerziellen Schriftarten, die oft mehrere tausend Glyphen beinhalten.
Die anderen beiden Achsen sind die bereits erwähnten PaCMAP-Koordinaten. So ergeben sich 2 bestimmte Betrachtungsweisen: Die Seitenansicht, die vor allem die Anzahl an Glyphen zeigt und die Ansicht von vorne, die eine Karte der Schriftfamilien symbolisiert.
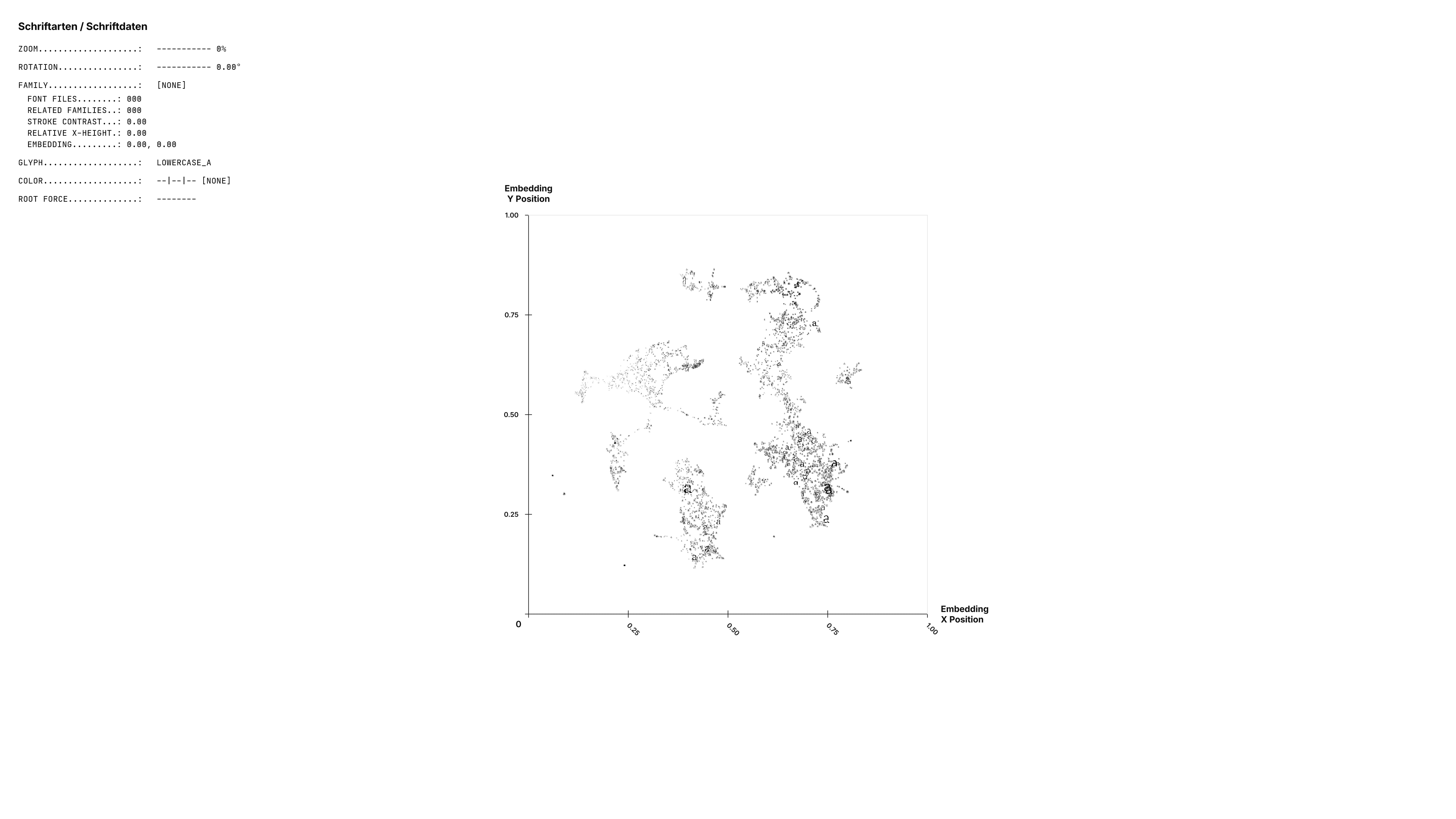
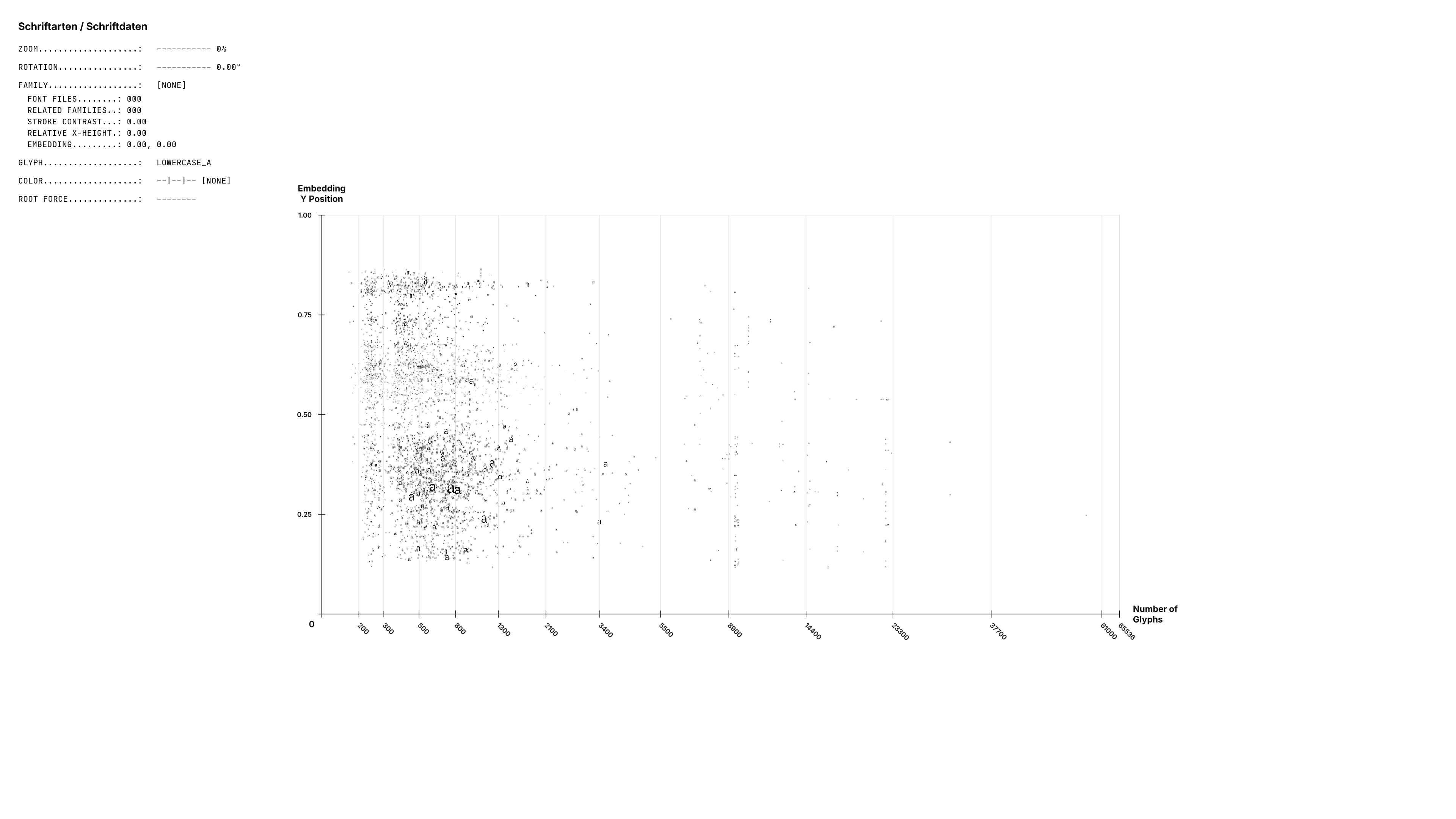
Edited by Lars Christian Schmidt on 2025-09-02.